
Highlights from Research Area C: Ensembles and adaptivity
Research area C was motivated by the vision of a global interactive forecasting system that was laid out within the THORPEX project. An optimal weather prediction system would be interactive in at least three different ways. First, an adaptive observation system could optimize the use of observational resources by targeting sensitive regions within the flow. Second, an adaptive ensemble prediction system could direct computational resources to best resolve the dominant sources of uncertainty in a particular weather situation. Finally, optimal guidance for decision makers would be obtained by adaptive forecast products that are tailored not only to the weather but also to the particular requirements of the users.
PANDOWAE research, with its focus on predictability and dynamical processes, has addressed a number of scientific challenges underlying that vision. Extensive data denial experiments, particularly in the framework of the T-PARC field experiment, gave insight into the methodology and impact of observation targeting. Multiscale modeling and stochastic methods were used to explore the impacts of different scales of motion on atmospheric predictability. In addition, detailed investigations of ensemble predictions systems allowed the quantitative assessment of the importance of different physical sources of uncertainty. Many of these studies were facilitated by access to the data bank of the THORPEX Interactive Grand Global Ensemble (TIGGE ), which provides the research community with effective access to global ensemble forecasts from most of the world’s important meteorological services.
a. Adaptive observing strategies (contributing to RA-C Question c1)
The core idea of observation targeting is to increase the density of measurements in regions where they are expected to have the most impact. So-called “sensitive regions ” can be computed by a number of methods, including singular vectors (SV), ensemble transform Kalman filter (ETKF), or ad hoc identification of important meteorological features. However, the different methods often point to different locations, and the impact of the observations depends on the forecasting system in which they are used. PANDOWAE researchers have investigated these issues, with a particular focus on the extratropical transition of tropical cyclones (ET), where observations and subsequent forecast performance are often poor. A general overview of observation targeting research, emphasizing the contributions of THORPEX research, is provided by Majumdar (2016).
An important opportunity for targeting research was provided by the T-PARC campaign, where a large number of dropsondes were released during ET events, guided by different targeting strategies (Weissmann et al. 2011a, Harnisch and Weissmann 2010). As illustrated by an example mission in Figure 1 (left panel), SV calculations tended to show the largest sensitivities in the remote environment of the cyclone, towards the midlatitudes, while ETKF sensitivities covered a broad region in the environment of the cyclone itself. Traditional tropical cyclone reconnaissance, on the other hand, has generally focused on the inner core of the cyclone. By assimilating only those dropsondes that were launched in a particular region, it was determined that observations in the cyclone environment have a consistent positive impact, while those in the remote environment had only a small effect. Observations of the core region produced large changes to the analysis, but little positive impact on forecast skill, probably because the models did not have sufficient resolution to reproduce the observed structures. Overall the targeted observations had a significant positive impact, but this was smallest in the ECMWF system, which had the best underlying analysis (Figure 1, right panel).
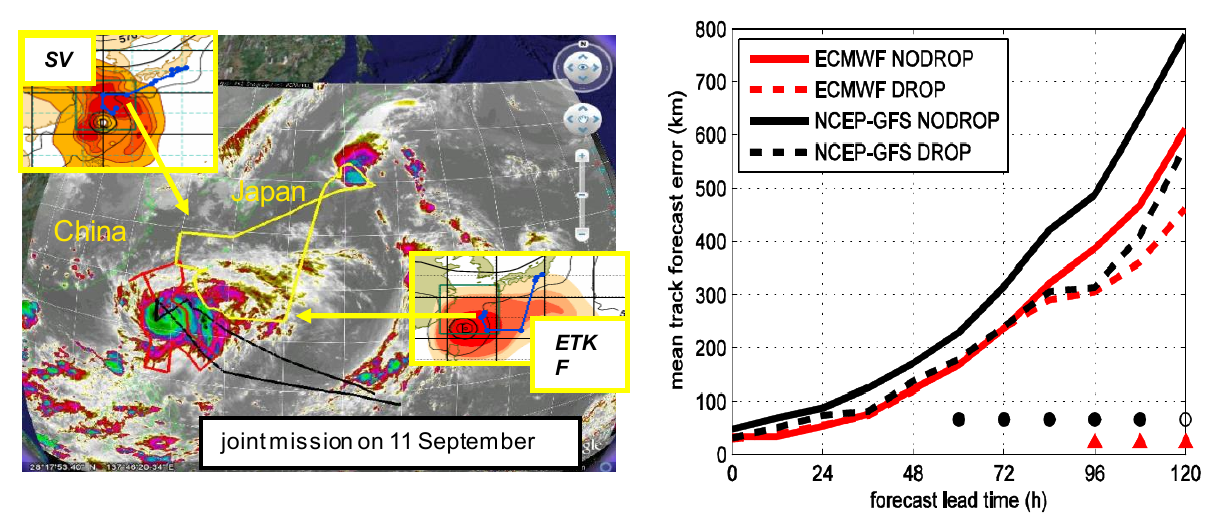
Figure 1: (left) Targeting guidance for Typhoon Sinlaku from SV and ETKF, valid at 1200 UTC 11 Sep 2008, overlaid on a satellite image with aircraft tracks. (right) Mean track forecast error as function of lead time for forecasts with and without dropsonde information in two weather prediction systems, averaged over three T-PARC events. Circle and triangle symbols indicate times where the impact of the dropsonde data is statistically significant. (Weissmann et al. 2011a)
These findings were supported and extended by a broader study of ET predictions in the Atlantic, using data denial experiments where routine observations were withheld in sensitive regions (Anwender et al. 2012). Sensitive regions were computed for eight cases using SVs. Different observation types were removed from ECMWF forecasts in those regions, which were typically in midlatitudes, and in the vicinity of the tropical cyclones. Observations in the tropical cyclone vicinity were found to be as important as those in the SV-predicted sensitive regions, and maximum forecast degradation occurred four days later. Satellite and aircraft observations were found to have the most impact, pointing to the importance of good observational coverage of the sensitive regions. A long term evaluation of targeted dropsondes from the Taiwanese DOTSTAR program (Chou et al. 2011) also showed a positive impact of observations in the cyclone vicinity, with track forecast improvements of 10-20%.
One option to improve coverage of a sensitive region is to employ novel observations, such as wind lidar measurements, that are equivalent to many dropsondes. Such an instrument was deployed on board the DLR Falcon during T-PARC, and the data was found to have a positive impact, which was strongest when fewer satellite and airc raft observations were available in the background data set
(Weissmann et al. 2011b).
b. The roles of different spatial and temporal scales in determining predictability (contributing to RA-C Questions c2, c3 and c4)
High impact weather phenomena, including heavy precipitation and strong winds, often occur on small spatial and temporal scales. Predictability of the large -scale environment is thus necessary for an accurate forecast, but not sufficient since rapid error growth on small scales can lead to large local uncertainties. An ensemble prediction system must represent uncertainties on the different scales that are relevant in different weather situations.
The interaction of different scales is a key challenge for convective precipitation. While there is sometimes a statistical relationship between the convective clouds and t he large scale flow, as assumed in cumulus parameterization schemes, the local distribution of the convection may be unpredictable. Techniques have been employed in PANDOWAE to identify the degree of control of convection by large-scale forcing and show the dependence of convective variability on this (Kober et al. 2012, 2014, Keil et al. 2013). In particular, it was found that when the large-scale forcing was sufficiently strong, the contribution of local perturbations to variance in precipitation forecasts was negligible, but local effects became increasingly important as the forcing becomes weaker. Since local triggering effects are rarely observed operationally, one solution to including them in an ensemble forecast is to use stochastic perturbations. A stochastic convective parameterization was implemented by Groenemeijer and Craig (2012) and tested in a variety of weather situations. Using a 100 member ensemble with 10 sets of boundary conditions from ECMWF ensemble members, each with 10
realizations of the stochastic convection scheme, the relative importance of the large and small scales was assessed by computing the variance of appropriate subensembles. Figure 2 shows that the “internal” variability due to the random convection increases with increasing precipitation rate and contributes about half of the total ensemble variance in precipitation for the weak forcing events. For
strong and medium forcing the contribution is smaller.
The representation of uncertainty in the large scales can be effectively explored using operational global ensembles. The ECMWF ensemble prediction system was found to be strongly underdispersive in cases of equatorward breaking of Rossby waves (Wiegand and Knippertz 2014). This was accompanied systematic errors where the wave breaking was too weak, leading to a northward displacement of PV streamers. Further insight was obtained using ensemble correlation analysis to identify patterns of precursors to the wave breaking events, showing how the different scales of motion are coupled. Coupling of scales in the other direction, upscale error growth, has been investigated using high resolution simulations of the response to small perturbations (Selz and Craig 2015a). The evolution was found to conform to a 3-stage process first described by Zhang et al. (2007), and subsequent investigation showed that the stochastic parameterization implemented by Groenemeijer and Craig (2012) was able to accurately represent the small scale uncertainty in this evolution (Selz and Craig 2015b).
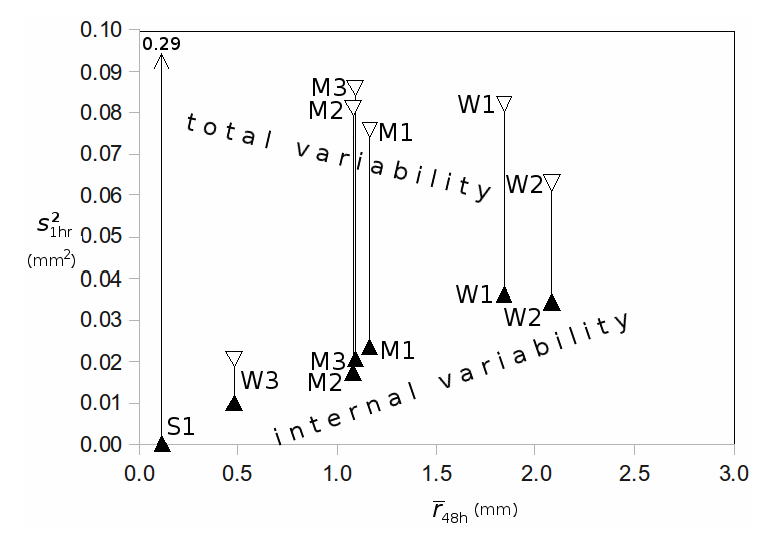
Figure 2: Variance of hourly precipitation for the full ensemble (open triangles) and for subensembles differing only in the stochastic convection scheme (solid triangles), averaged over 48 hr forecasts, plotted as function of mean precipitation rate. Points are plotted for events with strong (S), medium (M) and weak (W) large-scale forcing. (Groenemeijer and Craig 2012)
c. Sources of uncertainty in ensemble prediction systems (contributing to RA -C Questions c3, c4, c5 and c6)
A number of PANDOWAE projects analyzed existing ensemble predictions systems (EPS) to explore the contributions of different sources of uncertainty, as function of scale or physical process. The TIGGE archive proved particularly valuable since it contained data over a long period of time, with contributions from many EPS. Keller et al. (2011) used TIGGE data for 10 forecasts of ET events , from 8 different EPS. A cluster analysis was used to group the forecasts (over 200 per event) into distinct scenarios. Some EPS contributed to only a few scenarios, and some to many, but none to all. Figure 3 shows an example for Hurricane Ike (2008), where a cluster analysis of the ECMWF ensemble alone produces some scenarios (gray) that are found in clusters of the other TIGGE members (black) and some that are unique to ECMWF (blue).
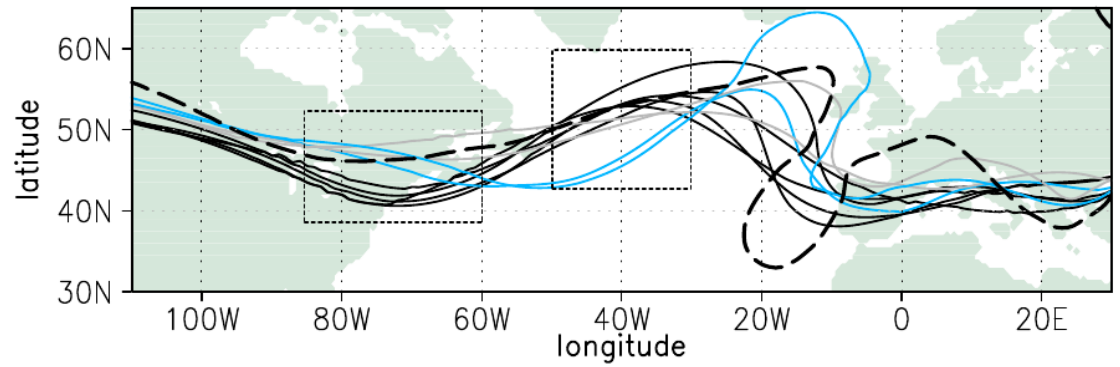
Figure 3: Spaghetti plots of 570 gpm isoline cluster means 48 h after investigation time (12 UTC 17 Sep 08, verifying analysis dashed). Grey and blue lines derived from ECMWF ensemble; black lines from TIGGE members with ECMWF excluded. (Keller et al. 2011)
TIGGE data has also been used to investigate the coupling between a heavy precipitation event on the south side of the Alps and an associated upper-level PV streamer (Wiegand et al. 2011). Precipitation was found to be well correlated with upper-level PV features in certain EPS, but weak in many, giving insight into how different models represent the interaction of PV with diabatic processes.
Over the two phases of PANDOWAE RA-C, many aspects of initial condition and process uncertainties have been investigated. The contributions of these various sources have been quantitatively compared in the cast of the ECMWF EPS by Lang et al. (2012). This EPS considers four sources of uncertainty: (i) EDA, an ensemble of data assimilations with perturbed observations, (ii) SKEB, a stochastic kinetic energy backscatter scheme to represent the impact of unresolved small scale motions, (iii) SPPT, stochastically perturbed parameterization tendencies to represent uncertainty in model physics, and (iv) SVINI, singular vector perturbations at the initial time to inflate the spread early in t he forecast. For 13 tropical cyclone events from 2008, the operational 51 member ensemble was compared with 21 member ensemble forecasts that used only one of the four sources. Figure 4 shows that while the spread of the full ensemble is similar to the RMS error, as desired, different sources contribute at different times. EDA dominates for about 24 h, but the other sources become more prominent at later times, with stochastic perturbations providing the largest source of spread after 48 h for about 40% of cases (Figure 4).
Quandt et al. (2017, 2018) investigated the forecast variability of the blocking system which was associated with the heat wave in Eastern Europe and Russia in summer 2010. They used three TIGGE forecasts from three different EPS to run a clustering (Quandt et al. 2017) and to apply an ensemble sensitivity analysis (Quandt et al. 2018). It was found that the onset of the block was better predicted than its decay (Quandt et al. 2017). During the block's mature stage, the predictability of the blocking ridge was high, while forecast uncertainties were associated with the upstream trough. The forecast variability of the block had an impact on the surface heat wave evolution and during the mature stage, also on the precipitation pattern over Western Europe (Quandt et al. 2017). In Quandt et al. (2018), different sources of uncertainty could be identified that were responsible for the forecast variability of the block. During the whole life-cycle of the block, its predictability depends on uncertainties in the prediction of diabatic processes (indicated by high values of the vertically integrated water vapor transport), Atlantic cyclone activity and of specific features in the upper-level wave pattern (such as Atlantic Rossby wave breaking).
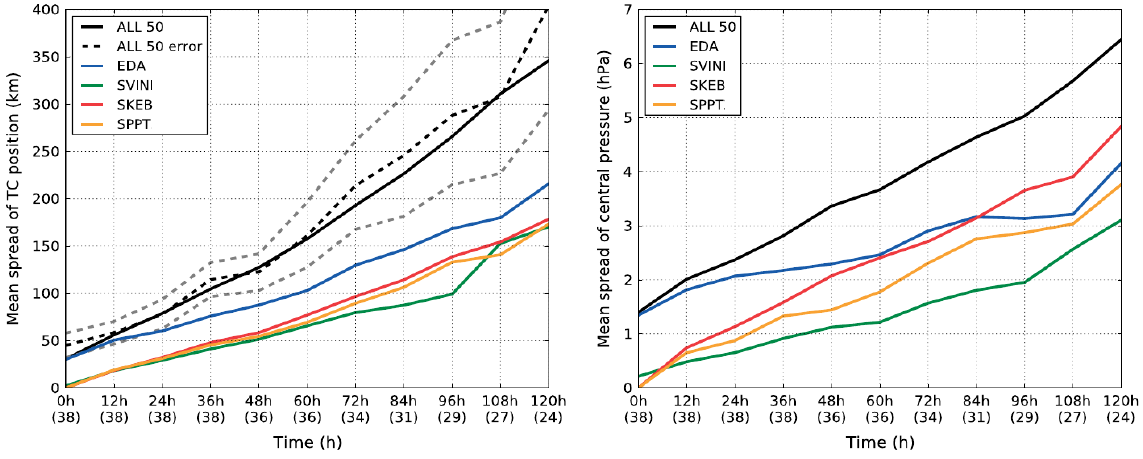
Figure 4: Mean ensemble spread of (left) TC track and (right) central pressure of the different ensembles. The dashed black line indicates the mean track error of the ALL50 ensemble-mean, with the dashed grey lines indicating the 95% confidence interval. Numbers in parentheses indicate how many forecasts were considered for the respective lead time. (Lang et al. 2012)